Gemeinsame Bearbeitung der Seiten der Website
Motivation
Die inhaltlichen Seiten der Website werden nach einem einheitlichen Schema halbautomatisch aus einer Themenvorgabe erzeugt. Die Beschreibung dazu findet sich hier.
Da sich mittlerweile eine dreistellige Zahl von Seiten ergeben hat, ist es schwer möglich, allgemein notwendige oder wünschenswerte Pflegemaßnahmen im Editor Seite für Seite sicher und konsistent durchzuführen. Daher werden die Seitendaten zu diesem Zweck aus der Webseite in das lokale Dateisystem exportiert, dort in der Regel mithilfe von python-scripts verarbeitet und dann wieder in die Webseite hochgeladen. Solche Pflegemaßnahem werden natürlich in der Staging-Area der Webseite durchgeführt und erst nach Fertigstellung der Arbeiten produktiv gesetzt.
Der Bearbeitungsprozess
Export aller Seiten
Zunächst wird der akutelle Produktionsstanad der Webseite in die Staging-Area überführt. Dies erfolgt in der Seitenadministration unter dem Punkt „Seite bearbeiten“.
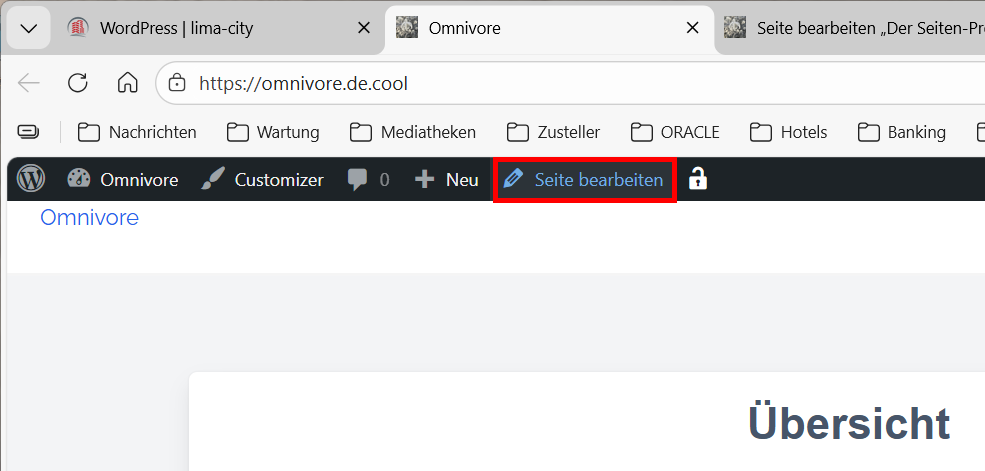
im folgenden Menü wird das Untermenü „Werkzeuge“ und darin die Funktion „Export“ aufgerufen.
Um den minimal zur Bearbeitung aller Seiten erforderlichen Export zu erstellen, wird die Option Custom Page(s) ausgewählt, in der Liste mit Strg+A alle Seiten ausgewählt und dann die Schaltfläche „Export-Daten herunterladen“ betätigt.
Der Browser zeigt dann an, das eine Datei zum Download bereitsteht. Der Dateiname wird automatisch mit dem Sitenamen-„WordPress“Datum.xml vorbelegt. Der Downlaod wird dann mit „Speichern unter“ gestartet.
Ich habe mir für die Ablage solcher Massendownloads ein separates Verzeichnis angelegt, dass ich dann in der folgenen Dateiauswahl ansteuere. Den Dateinamen ergänze ich um „-staging-single-pages“, um den Typ des Downloads festzuhalten. „Speichern“ schließt den Vorgang dann ab.
Nachbearbeitung des Exports
Es hat sich herausgestellt, dass der WordPress-Import-Prozess bestimmte Inhalte (Attatchments) der Website zusätzlich ergänzt statt ersetzt. Dies kann bei mehrfacher Export-Import-Verwendung zum exponentiellen Wachstum der Größe der Exportdatei führen.
Um dem vorzubeugen, kann folgendes Skript am besten nach jedem Gesamtexport verwendet werden:
deduplicate_attachments.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Bereinigt WordPress-WXR-Exporte:
1) Entfernt identische wp:postmeta-Blöcke innerhalb eines <item>
2) Normalisiert leere WordPress-typische Tags:
<tag/> -> <tag></tag>
Eigenschaften:
- CDATA-sicher (lxml)
- keine XML-Neuformatierung
- keine Änderung eingebetteten HTMLs
- diff-stabil
"""
import argparse
import os
import re
from lxml import etree as ET
WP_NS = {
"wp": "http://wordpress.org/export/1.2/"
}
def text(elem):
"""CDATA- und None-sicherer Textzugriff"""
return elem.text if elem is not None and elem.text is not None else ""
# -------------------------------
# Regex für leere WP-relevante Tags
# -------------------------------
EMPTY_WP_TAG_PATTERN = re.compile(
r"<(?P<tag>"
r"(?:"
r"wp:[\w\.\-]+|"
r"content:[\w\.\-]+|"
r"excerpt:[\w\.\-]+|"
r"description|"
r"language"
r")"
r")\s*/>"
)
def expand_empty_wp_tags(xml_text: str) -> str:
"""
Ersetzt <tag/> durch <tag></tag> für WordPress-typische, leere Tags.
- keine Attribute
- keine HTML-Void-Tags
- keine CDATA-Manipulation
"""
return EMPTY_WP_TAG_PATTERN.sub(
lambda m: f"<{m.group('tag')}></{m.group('tag')}>",
xml_text
)
# -------------------------------
# Hauptlogik
# -------------------------------
def main():
parser = argparse.ArgumentParser(
description="Deduplicate wp:postmeta and normalize empty WP tags (CDATA-safe)."
)
parser.add_argument(
"--xmlFile",
required=True,
help="WordPress-WXR-Exportdatei"
)
args = parser.parse_args()
in_file = args.xmlFile
if not os.path.isfile(in_file):
raise FileNotFoundError(in_file)
base, ext = os.path.splitext(in_file)
out_file = f"{base}_dedup_attach{ext}"
xml_parser = ET.XMLParser(
strip_cdata=False,
remove_blank_text=False,
recover=True
)
tree = ET.parse(in_file, xml_parser)
root = tree.getroot()
removed = 0
# --- Deduplication innerhalb jedes <item> ---
for item in root.findall(".//item"):
seen = set()
for pm in list(item.findall("wp:postmeta", namespaces=WP_NS)):
key_elem = pm.find("wp:meta_key", namespaces=WP_NS)
val_elem = pm.find("wp:meta_value", namespaces=WP_NS)
signature = (text(key_elem), text(val_elem))
if signature in seen:
item.remove(pm)
removed += 1
else:
seen.add(signature)
# --- CDATA-sichere Serialisierung ---
xml_bytes = ET.tostring(
tree,
encoding="utf-8",
xml_declaration=True
)
xml_text = xml_bytes.decode("utf-8")
# --- WordPress-konforme Normalisierung leerer Tags ---
xml_text = expand_empty_wp_tags(xml_text)
# --- Schreiben ---
with open(out_file, "w", encoding="utf-8", newline="\n") as f:
f.write(xml_text)
print("Bereinigung abgeschlossen")
print(f"Entfernte wp:postmeta-Duplikate: {removed}")
print(f"Ausgabedatei: {out_file}")
if __name__ == "__main__":
main()
Aufruf:
python .\deduplicate_attachments.py --xmlFile "t:\Wordpress\Massendownloads\omnivore.WordPress.2025-12-15-staging-single_pages.xml"Die Ausgabe erfolgt dann in die Ausgabedatei mit dem um „_dedup_attach“ erweiterten Dateinamen:
omnivore.WordPress.2025-12-15-staging-single_pages_dedup_attach.xml
Aus Convenience-Gründen ersetzt dieses Skript auch selbstschließende HTML-Tags <…/> in die Form <…></…>, da diese letzte Form von WordPress beim Export verwendet wird.
Inhaltliche Tags
#WordPressWartung #Seitenautomatisierung #StagingWorkflow #PythonSkripte #DatenexportImport #ContentPflege #TechnischeRedaktion #CMSProzess
Nachbearbeitung des Exports ergänzen: Split der Exportdatei wegen Größenbeschränkung für den IMport au 4 MB.
split-WXR.py –exportFile -> exportFile_1 … exportFile_n
Größe jeweils max. 3,9 MB, jeweils eine Wurzel, Angabe des übergeordneten Knotens zum Einhängen