Der Seiten-Produktionsprozess
Für die Erstellung der Seiten dieser WebSite habe ich einen Prozess entwickelt, der alle erforderlichen Schritte enthält und zu gut nutzbaren Ergebnissen in Form von WordPress-Seiten führt.
Arbeitsmittel
Alle Schritte der Seitenerstellung laufen
- als Prompt/Antwort-Schritt mit ChatGPT
- mit Bereitstellung von Daten für die weitere Verarbeitung
- mit manueller Speicherung dieser Daten in lokale Dateien
- mittels Copy/Paste
- mittels Dateidownload
- als lokaler Aufruf eines Python-Skripts
- mit Eingaben
- als Programmparameter
- als Eingabedatei via Dateipfad
- und Ausgaben
- als Ausgabe auf die Standardausgabe (i. d. R. zur Ablauf-/Inhaltskontrolle)
- als Ausgabedatei via Dateipfad
- mit Eingaben
ab.
Ablauf
Es gibt zwei Einstiegspunkte:
- Erstellung einer neuen Seite
- Überarbeitung einer bestehenden Seite
Vorbereitung der Seitenüberarbeitung
Bei der (nicht-trivialen) Überarbeitung einer Seite werden zunächst aus dem Python-Export der bestehenden Seite Informationen mittels eines Python-Skripts (.\strip_page.py) extrahiert und in Dateien bereitgestellt:
- Die Quellenliste mit MLA-Quellenbeschreibung und Link zum Online-Dokument für jede Quelle
- Autorenliste mit Lebensdaten, akademischem Grad, Position, Institut und Themenschwerpunkten
- Der Fließtext der Seite als einfacher Text ohne besondere Auszeichnungen
- dem Aufruf des Python-Skripts zu Seitenerstellung (build_page.py) mit den erforderlichen Parametern
- –inFile (Fließtext der Seite im HTML-Format)
- –sourceFile (Qualifizierte Quellenliste im BibText-Format)
- –authorFile (qualifizierte Autorenliste)
- –templateFile (Dateivorlage für die Struktur der WordPress-Exportseite mit Platzhalter für die inhaltlichen Informationen)
- –pageTitle (Seitentitel)
- –categories (WordPress-Kategorien für die erstellte Seite)
- –menu_order (Position der Seite in der Liste der Geschwisterseiten)
- –tags (Tags zu inhaltlichen Qualifikation der Seite)
strip_page.py
Code:
import re
import regex
import argparse
from pathlib import Path
def strip_wp_blocks(text: str) -> str:
"""
Entfernt WordPress-spezifische Blöcke und überflüssige Leerzeilen aus dem Text.
"""
text = re.sub(r"<!--.*?-->", "", text, flags=re.DOTALL)
text = re.sub(r'\s*class\s*=\s*(\\?")wp-block-heading\1', "", text, flags=re.IGNORECASE | re.MULTILINE)
text = re.sub(r"\n\s*\n", "\n", text)
return text.strip()
def extract_flowtext(xml_text: str) -> str:
"""
Extrahiert den Fließtext aus der XML-Datei bis vor das Quellenverzeichnis.
"""
m = re.search(
r"<content:encoded><!\[CDATA\[(.*?)<!-- wp:heading -->\n<h2 class=\"wp-block-heading\">(?:<strong>)?Quellenverzeichnis",
xml_text, flags=re.DOTALL)
if not m:
print("⚠️ Kein Fließtext gefunden.")
return ""
return strip_wp_blocks(m.group(1))
def clean_flowtext(text: str) -> str:
"""
Entfernt Fußnotenziffern, HTML-Tags und MLA-Inline-Zitate.
MLA-Zitate können mehrere Autoren oder Institutionen enthalten,
auch mit 'und' oder ';', sowie Buchstabenanhang bei Jahren (2023a).
"""
# 1. Fußnotenziffern-Links entfernen
text = re.sub(
r'<a href="[^#"]*#fn[^"]*"[^>]*><sup>\d+</sup></a>',
"",
text,
flags=re.IGNORECASE,
)
# 2. HTML-Tags entfernen
text = re.sub(r"<.*?>", "", text, flags=re.DOTALL)
# 3. MLA-Zitate entfernen
text = re.sub(
r"""\s*
\(
(?:
[^()0-9]*?
\s+\d{4}[a-z]?
(?:[,–\-]?\s*\d+)?
(?:\s*(?:und|;)\s*
[^()0-9]*?\s+\d{4}[a-z]?
(?:[,–\-]?\s*\d+)?
)*
)
\)
""",
"",
text,
flags=re.VERBOSE | re.UNICODE,
)
text = re.sub(r"\s{2,}", " ", text)
text = re.sub(r"\n\s*\n", "\n", text)
return text.strip()
def extract_sources(xml_text: str) -> str:
"""
Extrahiert die Quellen aus dem Quellenverzeichnis.
Minimalinvasive Anpassung:
- Entfernt die bisherige BibTeX-Ausgabe.
- Gibt stattdessen pro Quelleneintrag eine Zeile mit MLA-Quellenangabe (bis vor "zur Quelle")
und der URL aus.
- Trennzeichen: " | " (senkrechter Strich mit Leerzeichen).
"""
# Quellenverzeichnis finden (gekapselt oder ungekapselt)
block = re.search(
r'<div[^>]*class="[^"]*\bquellenverzeichnis\b[^"]*"[^>]*>(.*?)</div>',
xml_text, flags=re.DOTALL | re.IGNORECASE)
if not block:
block = re.search(
r'<h2 class="wp-block-heading">(?:<strong>)?Quellenverzeichnis(?:</strong>)?</h2>(.*?)(?=<h2 class="wp-block-heading">)',
xml_text, flags=re.DOTALL | re.IGNORECASE)
if not block:
print("⚠️ Kein Quellenverzeichnis gefunden.")
return ""
sources_html = block.group(1)
paras = re.findall(r"<p>(.*?)</p>", sources_html, flags=re.DOTALL | re.UNICODE)
output_lines = []
for para_html in paras:
# geschützte Leerzeichen u. ä. entfernen
para_html = re.sub(r"[\u00A0\u202F\u2000-\u200B]+", " ", para_html)
# MLA-Angabe bis vor "zur Quelle" extrahieren
mla_part = re.split(r"<a href=.*?>zur Quelle</a>", para_html, maxsplit=1)[0]
mla_plain = re.sub(r"<.*?>", "", mla_part).strip()
# URL extrahieren
url_match = re.search(r'<a href="([^"]+)">zur Quelle</a>', para_html)
url = url_match.group(1).strip() if url_match else "keine Online-Quelle gefunden"
# MLA + URL in einer Zeile zusammenführen
output_lines.append(f"{mla_plain} | {url}")
# Eine Zeile pro Quelle
return "\n".join(output_lines)
def extract_authors(xml_text: str) -> str:
"""
Extrahiert das Autorenverzeichnis (Autorenbiografien mit Fußnoten).
"""
block = re.search(
r"<h2 class=\"wp-block-heading\">(?:<strong>)?Autorenverzeichnis(?:</strong>)?</h2>(.*?)(?=<h2 class=\"wp-block-heading\">(?:<strong>)?Inhaltliche Tags)",
xml_text, flags=re.DOTALL)
if not block:
print("⚠️ Kein Autorenverzeichnis gefunden.")
return ""
section = block.group(1)
entries = re.findall(r"<p id=\"fn\d+\">(.*?)</p>", section, flags=re.DOTALL)
authors_out = []
for e in entries:
text = re.sub(r"<.*?>", "", e)
text = re.sub(r"\[\d+\]\s*", "", text)
text = text.replace("↩", "").strip()
authors_out.append(text)
return "\n".join(authors_out)
def extract_metadata(xml_text: str, out_dir: Path):
"""
Extrahiert Titel, Schlagwörter und Menüreihenfolge aus dem XML
und erzeugt ein Aufrufskript.
"""
title_m = re.search(r"<item>.*?<title>(?:<!\[CDATA\[)?(.*?)(?:\]\]>)?</title>", xml_text, flags=re.DOTALL)
title = title_m.group(1).strip() if title_m else "(unbekannt)"
tags = re.findall(r'<category domain="post_tag"[^>]*><!\[CDATA\[(.*?)\]\]></category>', xml_text)
tags = [f"#{t}" if not t.startswith("#") else t for t in tags]
# Menüreihenfolge extrahieren (ggf. mit CDATA)
menu_order_m = re.search(r"<wp:menu_order>(?:<!\[CDATA\[)?(\d+)(?:\]\]>)?</wp:menu_order>", xml_text)
menu_order = menu_order_m.group(1).strip() if menu_order_m else "0"
out_path = out_dir / "Aufruf_build_page.txt"
cmd = (
'python build_page.py `\n'
' --inFile "Fließtext.html" `\n'
' --sourceFile Quellenliste_BibTex.txt `\n'
' --authorFile Autorenliste.txt `\n'
' --templateFile Seitentemplate-omnivore-Blocks.xml `\n'
f" --pageTitle '{title}' `\n"
' --categories Thementext V6 `\n'
f" --menu_order {menu_order} `\n"
f" --tags '{' '.join(tags)}'\n"
)
out_path.write_text(cmd, encoding="utf-8")
def main():
parser = argparse.ArgumentParser(description="Extrahiert Inhalt und Metadaten aus WordPress-Exportdatei.")
parser.add_argument("--xmlFile", required=True, help="Pfad zur XML-Datei")
args = parser.parse_args()
xml_file = Path(args.xmlFile)
xml_text = xml_file.read_text(encoding="utf-8")
out_dir = Path(__file__).resolve().parent
flowtext = extract_flowtext(xml_text)
flowtext_clean = clean_flowtext(flowtext)
(out_dir / "Fließtext.html").write_text(flowtext_clean, encoding="utf-8")
# Ausgabe-Dateiname geändert: "Quellenliste.txt" statt BibTeX-Format
(out_dir / "Quellenliste.txt").write_text(extract_sources(xml_text), encoding="utf-8")
(out_dir / "Autorenliste.txt").write_text(extract_authors(xml_text), encoding="utf-8")
extract_metadata(xml_text, out_dir)
if __name__ == "__main__":
main()
Aufruf:
python .\strip_page.py --xmlFile "<Pfad zur WordPress-Exportdatei>"
Der Überarbeitungsprozess der Seite besteht dann darin, auf Basis der vorbereiteten Daten eine neue Seite gleicher Thematik zu erstellen, die die bisherige Seite in WordPress ablöst.
Erstellung des Seiteninhalts
Festlegung des Themas
Die inhaltliche Aufgabenstellung wird durch ein Thema (als Titel der Seite) bestimmt. Dazu gibt es ggf. weitere thematische Zusatzinformationen, die bei der Quellenauswahl und Texterstellung berücksichtigt werden.
Optionaler Prä-Dialog
Ein optionaler Vorbereitungsschritt kann ein „Prä-Dialog“ sein, ein Chat zwischen Autor („Ich“) und ChatGPT, um thematische Rahmenbedingungen in Erfahrung zu bringen und vorzuklären.
Falls interessant, kann der Prä-Dialog als HTML-Text bereitgestellt und an den Anfang des Seitenfließtextes (Datei .\Fließtext.html) eingefügt werden.
Quellenrecherche
Die Inhalte (fast) jeder Seite wird durch online verfügbare Literaturquellen untermauert.
Mittels Prompt wird ChatGPT (in der Variante ScholarGPT) damit beauftragt, qualifizierte Quellen inklusive Online-Fundstellen für die Literaturquellen für das Thema zu ermitteln und Angaben zur Quelle (Autor, Titel, URL, Abstract, …) bereitzustellen und gegenüber der Online-Fundstelle zu verifizieren.
Prompt Quellensuche
Suche fünf philosophische Primärquellen, systematische Übersichten oder grundlegende wissenschaftliche Arbeiten möglichst verschiedener Autoren aus unterschiedlichen Epochen zum Thema „Thema“.
Die Quellen sollen möglichst unterschiedliche wissenschaftliche Traditionen abdecken, insbesondere sowohl kontinentaleuropäische als auch anglo-amerikanische Perspektiven. Die Arbeiten sollen möglichst analytisch, sozialwissenschaftlich oder ökonomisch orientiert sein und nicht primär dem normativen oder moralphilosophischen Diskurs zuzuordnen sein.
Recherche- und Prüfregeln
- Führe eine tatsächliche Webrecherche durch und rufe die Zielseite jeder Quelle faktisch ab.
- Prüfe für jede Quelle folgende Punkte.
HTTP-Erreichbarkeit
Die Zielseite muss über HTTP erreichbar sein. Gib den tatsächlich ermittelten HTTP-Statuscode an.
Titelprüfung
Der Titel der Quelle auf der Zielseite muss mit dem im bibliografischen Eintrag angegebenen Titel übereinstimmen.
Autorenprüfung
Wenn ein Autor angegeben ist, muss er mit dem Urheber der Originalquelle übereinstimmen.
Publikationsdaten
Ermittle und dokumentiere Publikationsjahr sowie gegebenenfalls Verlag, Journal, Herausgeber, Übersetzer oder Edition.
- Verwende bevorzugt stabile wissenschaftliche Archive oder Verlagsseiten, insbesondere JSTOR, Internet Archive, HathiTrust, PhilPapers, Verlagsseiten oder Universitätsrepositorien.
- Wenn bibliografische Angaben aus der ursprünglichen Suche nicht vollständig mit den Daten der Zielseite übereinstimmen, übernimm die korrekten Daten aus der Zielseite.
- Eine Quelle gilt nur dann als bestätigt, wenn Titel, Autor und Publikationsdaten übereinstimmen und die Seite erreichbar ist.
Markiere bestätigte Quellen mit „Quelle bestätigt“.
Andernfalls „Quelle nicht bestätigt“.
Ausgabeformat
Für bestätigte Quellen verwende gültiges BibTeX-Format mit folgenden Feldern:
author
title
year
journal oder publisher (falls zutreffend)
url (stabile geprüfte Archivseite)
alturl (offizielle Verlagsseite oder alternative stabile Quelle)
note
abstract
Das Feld note enthält einen kurzen Verifikationsbericht mit HTTP-Status, Titelprüfung und Archivstabilität.
Das Feld abstract enthält zwei Abschnitte.
Inhalt – mindestens drei Sätze über Thema und Argumentation der Quelle.
Beitrag – mindestens zwei Sätze zum Beitrag der Quelle zum Thema „abhängige Nutzenfunktionen in Familien und sozialen Gruppen“.
Formatregeln
Die Ausgabe erfolgt ausschließlich als gültiger BibTeX-Block in einem Codefenster. Jeder Eintrag benötigt einen eindeutigen BibTeX-Key. Verwende UTF-8-Text.
Im Fall einer Seitenüberarbeitung können die bereits vorhandenen Quellen nochmals verifiziert und für die Seitenerstellung inhaltlich verwendet werden.
Prompt Verifikation vorhandener Quellen
Prüfe die folgenden Quellen:
[MLA-Quellen mit Links]
Recherche- und Prüfregeln
- Führe eine tatsächliche Webrecherche durch und rufe die Zielseite jeder Quelle faktisch ab.
- Prüfe für jede Quelle folgende Punkte.
HTTP-Erreichbarkeit
Die Zielseite muss über HTTP erreichbar sein. Gib den tatsächlich ermittelten HTTP-Statuscode an.
Titelprüfung
Der Titel der Quelle auf der Zielseite muss mit dem im bibliografischen Eintrag angegebenen Titel übereinstimmen.
Autorenprüfung
Wenn ein Autor angegeben ist, muss er mit dem Urheber der Originalquelle übereinstimmen.
Publikationsdaten
Ermittle und dokumentiere Publikationsjahr sowie gegebenenfalls Verlag, Journal, Herausgeber, Übersetzer oder Edition.
- Verwende bevorzugt stabile wissenschaftliche Archive oder Verlagsseiten, insbesondere JSTOR, Internet Archive, HathiTrust, PhilPapers, Verlagsseiten oder Universitätsrepositorien.
- Wenn bibliografische Angaben aus der ursprünglichen Suche nicht vollständig mit den Daten der Zielseite übereinstimmen, übernimm die korrekten Daten aus der Zielseite.
- Eine Quelle gilt nur dann als bestätigt, wenn Titel, Autor und Publikationsdaten übereinstimmen und die Seite erreichbar ist.
Markiere bestätigte Quellen mit „Quelle bestätigt“.
Andernfalls „Quelle nicht bestätigt“.
Ausgabeformat
Für bestätigte Quellen verwende gültiges BibTeX-Format mit folgenden Feldern:
author
title
year
journal oder publisher (falls zutreffend)
url (stabile geprüfte Archivseite)
alturl (offizielle Verlagsseite oder alternative stabile Quelle)
note
abstract
Das Feld note enthält einen kurzen Verifikationsbericht mit HTTP-Status, Titelprüfung und Archivstabilität.
Das Feld abstract enthält zwei Abschnitte.
Inhalt – mindestens drei Sätze über Thema und Argumentation der Quelle.
Beitrag – mindestens zwei Sätze zum Beitrag der Quelle zum Thema „abhängige Nutzenfunktionen in Familien und sozialen Gruppen“.
Formatregeln
Die Ausgabe erfolgt ausschließlich als gültiger BibTeX-Block in einem Codefenster. Jeder Eintrag benötigt einen eindeutigen BibTeX-Key. Verwende UTF-8-Text.
Dieser Prozess kann je nach Ergebnis iterativ mehrfach ausgeführt werden, bis eine qualitativ und quantitativ zufriedenstelle Quellenliste ermittel ist, die dann im BibTex-Format zum Copy/Paste bereitgestellt und manuell in eine lokale Datei (.\Quellenliste_BibTex.txt) übertagen wird.
Autorenliste
Aus der Quellenliste wird wird die Liste der Erst(genannten)-Autoren ermittelt, für die neben dem Namen biografische und thematische Informationen recherchiert und als Liste zum Copy/Paste bereitgestellt werden und manuell in eine Datei (.\Autorenliste.txt) übertragen werden.
Prompt Erstellung der Autorenliste
Gib eine reine Textliste (kein Markdown, keine Links, keine Formatierungen, auf Deutsch) mit jeweils einem Eintrag pro Zeile für die Erstautoren der Quellenliste aus. Doubletten sollen entfallen.
Ermittle für jeden Erstautor die biografischen Daten
- für Personen: Lebensdaten, falls verfügbar, sonst weglassen, akademischer Titel, Position, Institution, bis zu vier Themenschwerpunkte;
- für Institutionen: Name, ggf. geläufige Abkürzung, Gründungsjahr, Standort, bis zu vier Themenschwerpunkte
und gib diese Liste im Format
- für Personen: Vorname Nachname: (ggf. Lebensdaten,) Akademischer Grad, Position, Institution, Themenschwerpunkte
- für Institutionen: Name (ggf. Abkürzung): Gründungsjahr, Standort, Themenschwerpunkte
als einfache Textliste zum Copy/Paste mit einem Autoreneintrag je Zeile aus. Die Namen werden von den biografischen Daten durch einen Doppelpunkt : abgetrennt. Nicht zu ermittelnde Felder sollen vollständig weggelassen und nicht durch Auslassungszeichen dargestellt werden. Gib die Namen von Personen in der Form Vornamen Nachname aus.
Erstellung des Fließtextes der Seite
Zur Minderung der Komplexität der Aufgabenstellung Wird die Texterstellung in mehreren Bearbeitungsschritten durchgeführt.
Erstellung des Roh-Textes
Nun wird der Auftrag zur Erstellung eines Thementextes zum gegebenen Thema gepromptet. Der Prompt enthält neben dem Thema eine Reihe präziser Vorgaben für die Strukturierung und den Umfang des zu erstellenden Textes. Die Erstellung kann in mehreren Textabschnitten erfolgen.
Prompt Erstellung des Textes
Erstelle einen Thementext zum Thema „Thema“ basierend auf den vorliegenden Quellen in einer pluralistischen Sichtweise. Der Text gliedert sich in inhaltliche Abschnitte die verschiedene fachliche Perspektiven, inklusive einer kritischen Würdigung. Die Textlänge soll ca. 10000 Zeichen +/- 15% betragen. Der Text kann in mehreren Blöcken bereitgestellt werden. Überschriften werden nicht nummeriert. Formeln werden in LaTex (mit
, \\( \\) oder $$) formuliert.
Erstelle noch keine Quellenzitate.
Ermittlung wichtiger Begriffe
Nun werden die fachlichen Kerne aus Quellen für wichtige Begriffe im Text bestimmt. Der Prompt beschreibt das bewährte Vorgehen.
Prompt Ermittlung wichtiger Begriffe
1. Syntaktische Analyse des Roh-Texts
– Identifiziere Hauptsätze, Nebensätze und Einbettungen.
– Bestimme grundlegende Satzglieder.
2. Reduktion auf fachliche Kerne
– Berücksichtige den fachlichen Schwerpunkt des Roh-Textes.
– Extrahiere ausschließlich Begriffe, die exakt als Zeichenfolge im Text vorkommen
– Jeder Begriff muss 1:1 aus dem Text kopiert werden (Copy-Paste)
– Keine Paraphrasen, keine Abstraktionen, keine Generalisierungen
– Nur zusammenhängende Wörter oder Wortgruppen (Spans) sind erlaubt
– Wenn ein Begriff nicht exakt im Text auffindbar ist, darf er nicht verwendet werden
3. Niveauklassifikation
Ordne jedem Begriff genau ein Level (A–D) zu, basierend auf seinem kognitiven und fachlichen Anspruch:
– Level A – Allgemeinwissen
– Level B – Grundbegriffe
– Level C – Strukturbegriffe
– Level D – Expertenwissen
Zusätzliche Regeln:
– Die Einordnung erfolgt nur anhand des Begriffs selbst, ohne externe Ergänzungen.
– Im Zweifel ist die niedrigere Stufe zu wählen.
– Jeder Begriff darf genau ein Level erhalten.
Umsetzung für jeden gefundenen Begriff
– Erstelle ein json-Dictionary der Struktur
— term: Begriff in der im Text vorkommenden Form
— level: ermitteltes Level des terms
— description: Erläuterung des Terms mit einer Länge gemäß Level:
— A: ein Satz
— B: zwei Sätze
— C: drei Sätze
— D: vier bis fünf Sätze.
— Stelle das json-Directory im Codefenster zum Copy/Paste.
Ergänzung der MLA-Inline-Zitate
Darauf folgend wir der Auftrag gepromptet, an den passenden Stellen InLine-Zitate im MLA-Format in den Text einzufügen, die sich auf die Quellen im erstellten Quellenverzeichnis beziehen. Rahmenbedingugen dafür werden im Prompt übergeben.
Prompt Ergänzung Zitate
Ergänze den Text um Inline-Zitate im MLA-Stil „(Nachname/Institutionsname des Erstautors ggf. Jahr, Seitennummer falls bekannt)“ an den zu belegenden Stellen, ohne weitere Änderungen/Kürzungen am Text vorzunehmen. Die Seitenzahlen sind hilfreich, aber nicht zwingend. Der Text kann in mehreren Blöcken bereitgestellt werden. Zitiere nur Stellen im Text, wenn sie sich faktisch im Quellentext auffinden lassen (Angabe von Kapitel, Abschnitt, wenn vorhanden: Seitenzahl). Bei fehlender Fundstelle oder Unsicherheit: Zitat entfernen oder Quelle ohne Seitenzahl im Fließtext nennen. Stelle im Prüfprotokoll entsprechend markieren.
Ein Inline-Zitat darf nur gesetzt werden, wenn die zitierte Information faktisch in der angegebenen Quelle auffindbar ist.
Nachname oder Institution im Zitat = Erstautor der Quelle im Literaturverzeichnis. Abweichungen (Übersetzer, Herausgeber) nur, wenn für die Stelle relevant.
Jahreszahl = Publikationsjahr der verwendeten Ausgabe. Bei antiken Werken → Jahr der Edition im Verzeichnis angeben.
Seitenangaben: Falls aus den verfügbaren Informationen ermittelbar.
Format: (Autor Jahr, Seite) oder (Autor Jahr).
Falls möglich, soll das Zitat im Original überprüft werden: Begriff oder Aussage existiert. Interpretation ist durch Text gedeckt.
Prüfprotokoll: Für jede Quelle anlegen: Zitierstelle im eigenen Text, Vergleichsstelle im Original (Kapitel, Abschnitt, Seite falls verfügbar) HTTP-Status / Zugriffsweg (Archive.org, Gutenberg, Verlag, etc.).
Maßnahmen bei Unsicherheit: Stelle nicht auffindbar → Zitat entfernen oder allgemein formulieren. Nur Quelle im Fließtext nennen, ohne Klammern. Im Protokoll als ❌ markieren.
Wenn die Ermittlung von Seitenzahlen oder Abschnitten nicht möglich, ist für Inline-Zitate die Form (Autor, Jahr) MLA-konform.
Füge das Prüfprotokoll am Ende des Textes unter der Überschrift „Prüfprotokoll der Zitierstellen“ an.
Formatierung als HTML-Text
Dann wird der Auftrag gepromptet, den erstellten und mit Zitaten versehenen Text in HTML-Text zu übertragen. Auch hierbei werden Rahmenbedingungen im Prompt übermittelt.
Prompt HTML-Formatierung
Stelle den gesamten erstellten Originaltext ohne Gesamttitel im HTML-Format und ggf. eingebettetem LaTex (mit [ ], ( ) oder $$) im einem HTML-Codefenster zum einfachen Copy/Paste zur Verfügung. Das Überschriftenlevel beginnt mit H2. Das Prüfprotokoll soll als HTML-Tabelle ausgegeben werden. Latex-Ausdrücke werden nicht in <pre>-Blöcke gekapselt. WordPress-Block-Kommentare sollen hier nicht eingefügt werden.
Der erstellte HTML-Text wird zum Copy/Paste bereitgestellt und manuell in eine lokale Datei (.\Fließtext.html) übertragen.
Ermittlung der Tags
Folgend wird nach bis zu acht inhaltlichen Tags gepromptet, die die Inhalte des erstellten Textes charakterisieren. Ziel ist es, eine navigierbare Tag-Cloud über die Seiten der Web-Instanz zu erstellen.
Prompt Tag-Ermittlung
Ermittle ca. 8 fachliche Tags und gib sie im #EinWort-Format aus. Autoren und Quellentitel sollten keine Tags sein.
Beispiel: #Kultursoziologie #ThomasLuckmann #Wissenssoziologie #Phänomenologie #Konstruktionismus #Kommunikationstheorie #Sozialtheorie #SoziologieDerKultur
Die Tags werden beim Aufruf des Python-Skripts zu Seitenerstellung (build_page.py) als Parameter (–tags ‚…‘) übergeben.
Optionaler Post-Dialog
Ein optionaler Nachbetrachtungsschritt kann ein „Post-Dialog“ sein, ein Chat zwischen Autor („Ich“) und ChatGPT, um inhaltliche Einschätzungen des ertellten Textes zu reflektieren.
Falls interessant, kann der Post-Dialog als HTML-Text bereitgestellt und an das Ende des Seitenfließtextes (Datei .\Fließtext.html) eingefügt werden.
Erstellung der WordPress-Exportdatei
Die befüllten Dateien sowie die die Parameter des Titels und der Tags werden – neben technischen anderen Parametern – an ein lokales Python-Skript übergeben, das aus diesen Daten eine WordPress-Exportdatei erstellt.
build_page.py
import re
import argparse
from datetime import datetime, timedelta
from pathlib import Path
# ==============================================================
# Hilfsfunktionen
# ==============================================================
# Rollen-/Funktionszusätze bei Personen, die KEINE Namenssynonyme darstellen
ROLE_SUFFIXES = {
"hrsg.", "hg.", "herausgeber",
"ed.", "eds.",
"übers.", "übersetzer", "translator",
"kommentar", "kommentiert von"
}
def generate_slug(title: str) -> str:
slug = title.lower()
slug = slug.replace("ä","ae").replace("ö","oe").replace("ü","ue").replace("ß","ss")
slug = re.sub(r"[^a-z0-9\-]+","-", slug).strip("-")
return slug
def generate_name_synonyms(fullname: str) -> list[str]:
"""
Erzeugt alle gängigen Varianten eines Autorennamens:
Personen:
- Nachname
- Vorname Nachname
- Initial(en) Nachname
- Nachname, Vorname / Nachname, Initial(en)
- Varianten mit Präfixen (von, van, de, …)
Institutionen:
- Vollform
- Alias in Klammern als eigenständiges Synonym
- Alias mit und ohne Klammern
Rollenangaben wie (Hrsg.), (Hg.), (Übers.) werden ignoriert.
"""
# Normalisieren
name = fullname.strip()
name = re.sub(r"\s+", " ", name)
# ----------------------------------------------------------
# Behandlung von Klammerzusätzen
# ----------------------------------------------------------
m = re.match(r"^(.*?)\s*\(([^()]+)\)$", name)
if m:
base = m.group(1).strip()
bracket = m.group(2).strip()
bracket_lc = bracket.lower().rstrip(".")
# Fall 1: Personeller Rollen-Zusatz → ignorieren
if bracket_lc in ROLE_SUFFIXES:
name = base
# Fall 2: Institutioneller Alias → eigene Synonymlogik
else:
variants = {
fullname, # Vollform mit Klammern
base, # ohne Klammern
bracket, # Alias ohne Klammern (für Inline-Zitate)
f"({bracket})" # Alias mit Klammern
}
return sorted(v for v in variants if v)
# ----------------------------------------------------------
# Personenlogik (Originalcode)
# ----------------------------------------------------------
# Liste typischer Namenspräfixe, die zum Nachnamen gehören
prefixes = {
"von", "van", "de", "del", "der", "den", "du", "da", "di",
"le", "la", "mac", "mc", "o’", "o'", "ap", "fitz",
"bin", "al", "el", "ibn"
}
tokens = name.split(" ")
# 1. Präfix-Segment ab letztem passenden Token
split_index = 0
for i, tok in enumerate(tokens):
if tok.lower().rstrip(",") in prefixes:
split_index = i
break
if split_index > 0:
firstnames = tokens[:split_index]
lastnames = tokens[split_index:]
else:
firstnames = tokens[:-1]
lastnames = tokens[-1:]
# Initialen bilden
initials = [f"{fn[0]}." for fn in firstnames if fn]
initial_str = " ".join(initials)
full_first = " ".join(firstnames)
last = " ".join(lastnames)
variants = set()
# Basisvarianten
variants.add(last) # Nachname
if full_first:
variants.add(f"{full_first} {last}") # Vorname Nachname
variants.add(f"{last}, {full_first}") # Nachname, Vorname
if initials:
variants.add(f"{initial_str} {last}") # K. O. Meier
variants.add(f"{last}, {initial_str}") # Meier, K. O.
if len(firstnames) > 1:
variants.add(f"{firstnames[0]} {initial_str} {last}") # Karl O. Meier
# Fallback: nur letzter Teil ohne Präfix
if len(lastnames) > 1 and lastnames[0].lower() in prefixes:
variants.add(lastnames[-1])
# vereinheitlichen
cleaned = []
for v in variants:
v = re.sub(r"\s+", " ", v.strip())
v = v.replace(" ,", ",")
cleaned.append(v)
return sorted(set(cleaned))
def insert_footnotes(text: str, sourceFile: str, slug: str, authorFile: str) -> tuple[str, list]:
"""
Fügt Fußnoten nach der ersten Nennung jedes Autors im Text ein.
Verwendet Synonymlisten zur Steigerung der Trefferquote.
Gibt den veränderten Text und die verwendeten Autoren zurück.
"""
authors = []
lines = Path(authorFile).read_text(encoding="utf-8").splitlines()
print("=== DEBUG: Synonymlisten pro Autor ===")
for line in lines:
if ":" not in line:
continue
name_part = line.split(":", 1)[0].strip()
syns = generate_name_synonyms(name_part)
authors.append((name_part, syns))
print(f"Autor: {name_part}")
for s in syns:
print(f" - {s}")
print("-" * 40)
print("=== Ende der Synonymlisten ===\n")
# Entferne ggf. alte Fußnoten aus vorherigen Läufen
text = re.sub(
rf'<a href="/{re.escape(slug)}#fn\d+" id="fnref\d+"><sup>\d+</sup></a>',
"",
text
)
used = []
author_to_num = {}
counter = 1
# Für jeden Autor: erste Fundstelle eines Synonyms markieren
for main_name, syns in authors:
matches = []
for syn in syns:
for m in re.finditer(rf"\b{re.escape(syn)}\b", text):
matches.append((m.start(), m.end(), syn))
if not matches:
continue
# Früheste Fundstelle auswählen
matches.sort(key=lambda x: x[0])
start, end, best_syn = matches[0]
# Fußnotennummer zuweisen
num = counter
author_to_num[main_name] = num
used.append((num, main_name))
counter += 1
# Nur an dieser Fundstelle markieren
pattern = re.compile(rf"\b{re.escape(best_syn)}\b")
text = pattern.sub(
rf'\g<0><a href="/{slug}#fn{num}" id="fnref{num}"><sup>{num}</sup></a>',
text,
count=1
)
return text, used
# ==============================================================
# Phase 1 – generische Blockumwandlung
# ==============================================================
def wrap_generic_blocks(text: str) -> str:
"""Markiert Standard-HTML-Elemente als Gutenberg-Blöcke, ohne <details>/<table> zu verändern."""
text = re.sub(r"<h2([^>]*)>", r"<!-- wp:heading -->\n<h2 class=\"wp-block-heading\"\1>", text, flags=re.I)
text = re.sub(r"</h2>", r"</h2>\n<!-- /wp:heading -->", text, flags=re.I)
for level in range(3, 7):
text = re.sub(
rf"<h{level}([^>]*)>",
rf"<!-- wp:heading {{\"level\":{level}}} -->\n<h{level} class=\"wp-block-heading\"\1>",
text, flags=re.I)
text = re.sub(rf"</h{level}>", rf"</h{level}>\n<!-- /wp:heading -->", text, flags=re.I)
text = re.sub(r"<p([^>]*)>", r"<!-- wp:paragraph -->\n<p\1>", text, flags=re.I)
text = re.sub(r"</p>", r"</p>\n<!-- /wp:paragraph -->", text, flags=re.I)
text = re.sub(r"<ul([^>]*)>", "<!-- wp:list -->\n<ul class=\"wp-block-list\"\\1>", text, flags=re.I)
text = re.sub(r"</ul>", "</ul>\n<!-- /wp:list -->", text, flags=re.I)
text = re.sub(r"<ol([^>]*)>", "<!-- wp:list {\"ordered\":true} -->\n<ol class=\"wp-block-list\"\\1>", text, flags=re.I)
text = re.sub(r"</ol>", "</ol>\n<!-- /wp:list -->", text, flags=re.I)
text = re.sub(r"<li([^>]*)>", r"<!-- wp:list-item -->\n<li\1>", text, flags=re.I)
text = re.sub(r"</li>", r"</li>\n<!-- /wp:list-item -->", text, flags=re.I)
text = re.sub(r"<div class=\"([^\"]*)\">", r"<!-- wp:group -->\n<div class=\"\1\">", text, flags=re.I)
text = re.sub(r"</div>", r"</div>\n<!-- /wp:group -->", text, flags=re.I)
return text
# ==============================================================
# Phase 2 – WP-konforme Details-Blöcke + Prüfprotokoll
# ==============================================================
def build_display_blocks(text: str) -> tuple[str, str]:
"""Erkennt alle <details>-Blöcke, baut sie WP-konform um.
Gibt zusätzlich den separaten Prüfprotokoll-Block zurück."""
quotation_block = ""
# Sonderfall: Prüfprotokoll der Zitierstellen
pattern = re.compile(
r'(?:<!--\s*wp:heading\s*-->\s*)?<h2[^>]*>\s*Prüfprotokoll der Zitierstellen\s*</h2>'
r'(?:\s*<!--\s*/wp:heading\s*-->)?\s*(?:<!--\s*wp:table\s*-->\s*)?(<table.*?</table>)',
re.IGNORECASE | re.DOTALL
)
match = pattern.search(text)
if match:
table_block = match.group(1)
table_block = re.sub(r"<!--\s*/?wp:table\s*-->", "", table_block)
quotation_block = (
'<!-- wp:details {"className":"wp-block-details"} -->\n'
'<details class="wp-block-details">\n'
'<summary>Prüfprotokoll der Zitierstellen</summary>\n'
'<!-- wp:html -->\n'
'<figure class="wp-block-table">\n'
f'{table_block.strip()}\n'
'</figure>\n'
'<!-- /wp:html -->\n'
'</details>\n'
'<!-- /wp:details -->'
)
text = pattern.sub("", text, 1)
else:
print("Prüfprotokoll der Zitierstellen fehlt!")
# Generische Details-Umwandlung
def convert_details(m):
block = m.group(0)
summary_match = re.search(r"<summary[^>]*>(.*?)</summary>", block, flags=re.S | re.I)
summary = summary_match.group(1).strip() if summary_match else "Details"
table_match = re.search(r"<table[^>]*>.*?</table>", block, flags=re.S | re.I)
if table_match:
table_html = table_match.group(0)
figure_block = (
'<!-- wp:table {"className":"wp-block-table"} -->\n'
'<figure class="wp-block-table">\n'
f'{table_html.strip()}\n'
'</figure>\n'
'<!-- /wp:table -->'
)
inner_html = figure_block
else:
inner_html = re.sub(r"</?(details|summary)[^>]*>", "", block, flags=re.S | re.I).strip()
return (
'<!-- wp:details {"className":"wp-block-details"} -->\n'
f'<details class="wp-block-details">\n'
f'<summary>{summary}</summary>\n'
f'{inner_html}\n'
'</details>\n'
'<!-- /wp:details -->'
)
text = re.sub(r"<details[^>]*>.*?</details>", convert_details, text, flags=re.S | re.I)
return text, quotation_block
# ==============================================================
# Quellen, Autoren, Kategorien, Template
# ==============================================================
def parse_bibtex_sources(sourceFile: str) -> list[dict]:
text = Path(sourceFile).read_text(encoding="utf-8")
entries = []
for raw in re.split(r"@\w+{", text)[1:]:
fields = {m.group(1).lower(): m.group(2).strip()
for m in re.finditer(r"(\w+)\s*=\s*[{\"]([^{}\"]+)[}\"]", raw)}
entries.append(fields)
return entries
def build_sources(sourceFile: str) -> str:
sources = parse_bibtex_sources(sourceFile)
out = [
'<!-- wp:heading -->',
'<h2 class="wp-block-heading"><strong>Quellenverzeichnis</strong></h2>',
'<!-- /wp:heading -->',
'<!-- wp:group {"className":"quellenverzeichnis"} -->',
'<div class="wp-block-group quellenverzeichnis">'
]
for s in sources:
author = s.get("author", "").strip()
title = s.get("title", "").strip()
year = s.get("year", "").strip()
publisher = s.get("publisher", "").strip()
url = s.get("url", "").strip()
doi = s.get("doi", "").strip()
verification = s.get("annotation", "").strip() or s.get("note", "").strip()
abstract = s.get("abstract", "").strip()
mla = f"{author}. <i>{title}</i>. {publisher}, {year}."
if url:
entry = f"{mla} <a href=\"{url}\">zur Quelle</a>"
elif doi:
entry = f"{mla} <a href=\"https://doi.org/{doi}\">zur Quelle</a>"
else:
entry = f"{mla} <em>(keine Online-Quelle)</em>"
if verification:
entry += f" {verification}"
out.append(f"<!-- wp:paragraph -->\n<p>{entry}</p>\n<!-- /wp:paragraph -->")
# Abstract-Inhalt als Details-Block
if abstract:
parts = re.split(r"Beitrag\s*:\s*", abstract, flags=re.IGNORECASE)
inhalt = parts[0].strip()
beitrag = parts[1].strip() if len(parts) == 2 else ""
details = [
'<!-- wp:details {"className":"wp-block-details"} -->',
'<details class="wp-block-details">',
'<summary>Inhalt</summary>',
f'<!-- wp:paragraph -->\n<p>{inhalt}</p>\n<!-- /wp:paragraph -->'
]
if beitrag:
details.append(f'<!-- wp:paragraph -->\n<p>Beitrag: {beitrag}</p>\n<!-- /wp:paragraph -->')
details.append('</details>\n<!-- /wp:details -->')
out.append("\n".join(details))
out.append("</div>\n<!-- /wp:group -->")
return "\n".join(out)
def build_authors(authorFile: str, used: list, slug: str) -> str:
lines = Path(authorFile).read_text(encoding="utf-8").splitlines()
author_map = {ln.split(":",1)[0].strip(): ln.split(":",1)[1].strip() for ln in lines if ":" in ln}
out = [
'<!-- wp:heading -->',
'<h2 class="wp-block-heading"><strong>Autorenverzeichnis</strong></h2>',
'<!-- /wp:heading -->'
]
seen=set()
for num,name in used:
if name in seen: continue
seen.add(name)
bio = author_map.get(name,"")
out.append(f"<!-- wp:paragraph -->\n<p id='fn{num}'>[{num}] {name}: {bio} <a href='/{slug}#fnref{num}'>↩</a></p>\n<!-- /wp:paragraph -->")
return "\n".join(out)
def build_category_tags(categories: list, tags: list) -> tuple[str, str]:
"""Erzeugt XML-Kategorien für Kategorien und Tags."""
cat_xml = "\n".join(
[f'<category domain="category" nicename="{c.lower()}"><![CDATA[{c}]]></category>' for c in categories]
)
tag_xml = "\n".join(
[f'<category domain="post_tag" nicename="{t.lower()}"><![CDATA[{t}]]></category>' for t in tags]
)
hashtag_str = " ".join(tags)
return cat_xml + "\n" + tag_xml, hashtag_str
def fill_template(templateFile: str, title: str, slug: str,
flowtext: str, sources: str, authors: str,
quotation_block: str, categories_xml: str, tags: str,
menu_order: int = 0) -> str:
xml = Path(templateFile).read_text(encoding="utf-8")
plain = re.sub(r"<[^>]+>", "", flowtext)
zeichen, woerter = len(plain), len(plain.split())
now = datetime.now()
replacements = {
"§§§title": title,
"§§§slug": slug,
"§§§variabler_inhalt": flowtext,
"§§§zeichen": str(zeichen),
"§§§woerter": str(woerter),
"§§§QUELLENBLOCK": sources,
"§§§AUTORENBLOCK": authors,
"§§§QUOTATION_CHECKS": quotation_block,
"§§§menu_order": str(menu_order),
"§§§post_tag": tags,
"<category domain=\"category\" nicename=\"§§§category\"><![CDATA[§§§category]]></category>": categories_xml,
"§§§post_date": now.strftime("%Y-%m-%d %H:%M:%S"),
"§§§post_date_gmt": (now - timedelta(hours=2)).strftime("%Y-%m-%d %H:%M:%S")
}
for k,v in replacements.items():
xml = xml.replace(k,v)
return xml
# ==============================================================
# Hauptprogramm
# ==============================================================
def main():
p = argparse.ArgumentParser()
p.add_argument("--inFile", required=True)
p.add_argument("--sourceFile", required=True)
p.add_argument("--authorFile", required=True)
p.add_argument("--templateFile", required=True)
p.add_argument("--pageTitle", required=True)
p.add_argument("--categories", nargs="+", default=["Philosophie"])
p.add_argument("--tags", nargs="+", default=["Philosophie"])
p.add_argument("--menu_order", type=int, default=0)
a = p.parse_args()
slug = generate_slug(a.pageTitle)
flowtext = Path(a.inFile).read_text(encoding="utf-8")
flowtext = re.sub(r"</?(html|body)[^>]*>", "", flowtext, flags=re.I)
flowtext, used = insert_footnotes(flowtext, a.sourceFile, slug, a.authorFile)
flowtext = wrap_generic_blocks(flowtext)
flowtext, quotation_block = build_display_blocks(flowtext)
sources = build_sources(a.sourceFile)
authors = build_authors(a.authorFile, used, slug)
categories_xml, hashtag_str = build_category_tags(a.categories, a.tags)
xml = fill_template(
a.templateFile, a.pageTitle, slug,
flowtext, sources, authors, quotation_block,
categories_xml, hashtag_str, a.menu_order
)
Path(f"{slug}.xml").write_text(xml, encoding="utf-8")
print(f"✅ Seite exportiert: {slug}.xml")
if __name__ == "__main__":
main()
python .\build_page.py `
--inFile ".\Fließtext.html" `
--sourceFile .\Quellenliste_BibTex.txt `
--authorFile .\Autorenliste.txt `
--templateFile .\Seitentemplate-omnivore-Blocks.xml `
--pageTitle '<Seitentitel>' `
--categories <WordPress-Kategorien> `
--menu_order <Position in Seitenliste> `
--tags '<#Tag-Liste>'Das Skript erzeugt bei fehlerfreiem Ablauf eine WordPress-Exportdatei. Der Name wird dabei als ’slug‘ aus dem Titel der Seite abgeleitet und mit der Dateierweiterung .xml im lokalen Verzeichnis abgelegt.
Fußnotenziffern für Autoren
In den Fließtext werden Fußnotenziffern mit hinterlegten Links bei der jeweils ersten Nennung eines Autorennamens (Nachname) aus der Autorenliste eingefügt. Der Link hinter Fußnotenziffer navigiert zum entsprechenden Eintrag im Autorenverzeichnis, der Zurück-Link im Autorenverzeichnis navigiert zurück zur Fußnotenziffer.
Hochladen der Datei nach WordPress
Sollte die Seite bereits in in der WordPress-Instanz vorhanden sein, muss sie dort vor dem Hochladen in den Papierkorb verschoben und dann endgültig gelöscht werden!
Zum Upload von WordPress-Exportdateien wird das PlugIn WordPress Importer verwendet.
Aufruf PlugIn „Daten importieren“
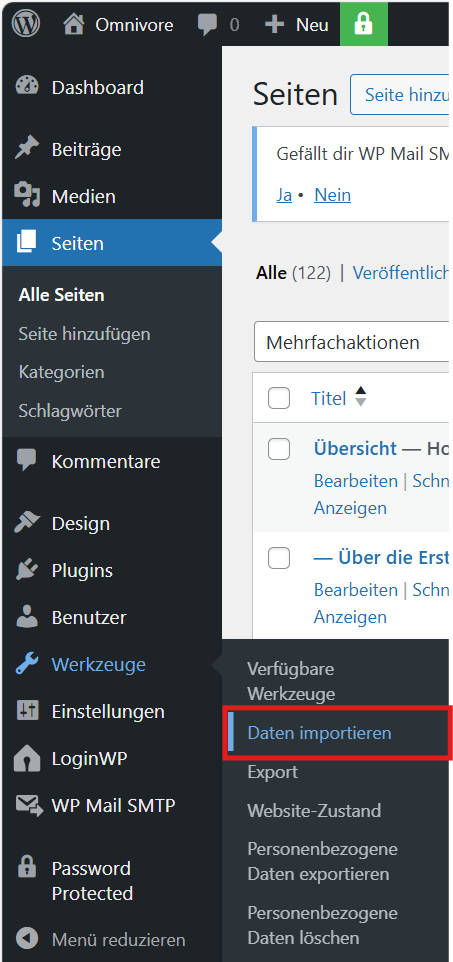
Nach Aufruf des Plugins über das Werkzeug-Menü wird die Datei ausgewählt und mit den Standard-Parametern hochgeladen.
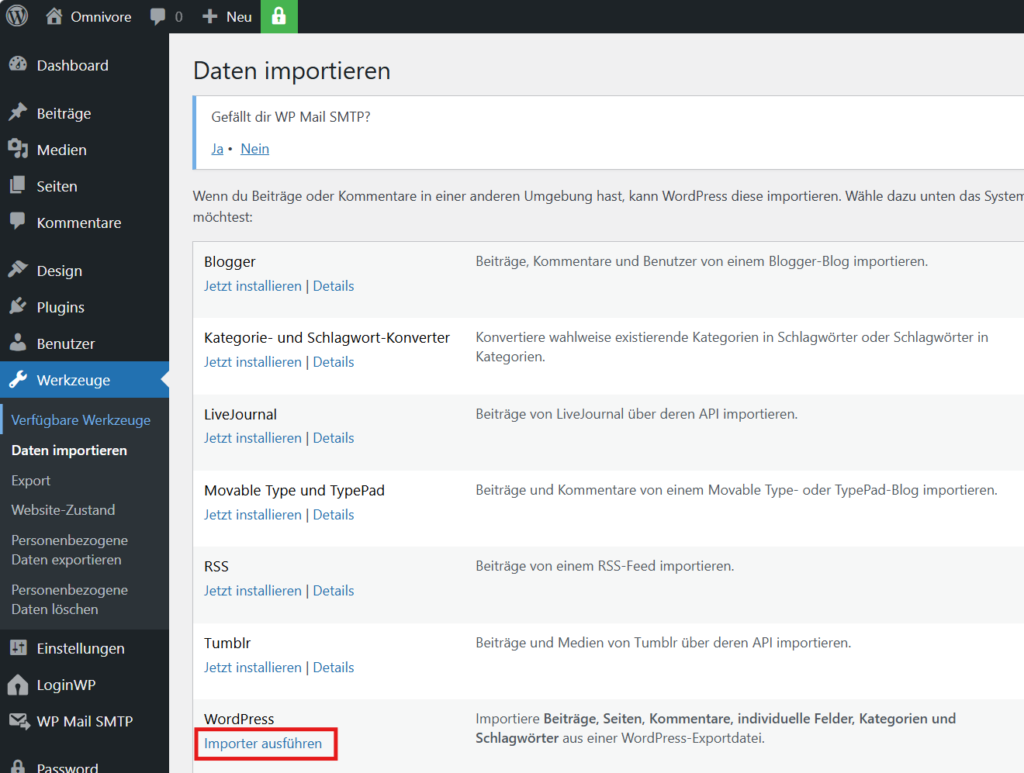
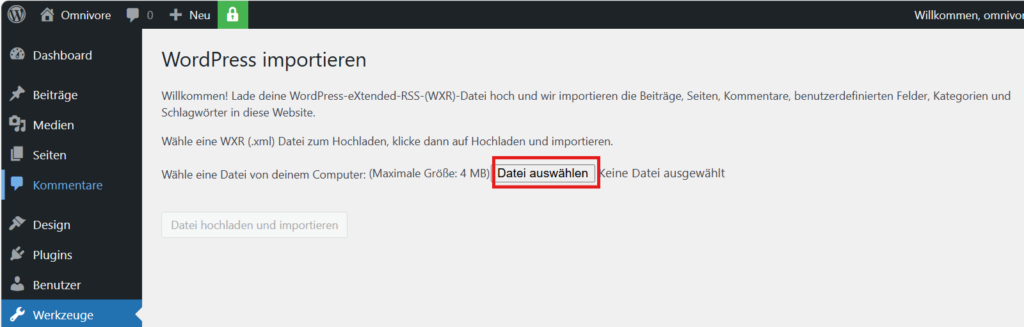
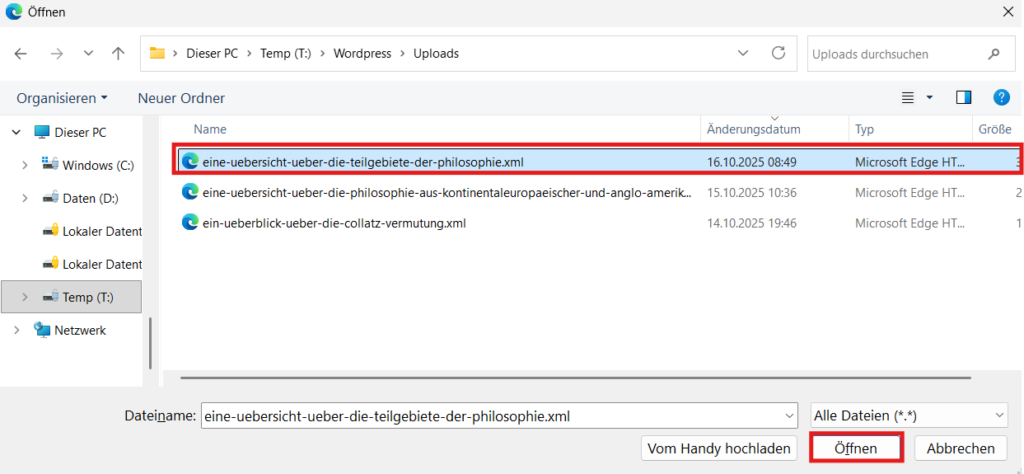
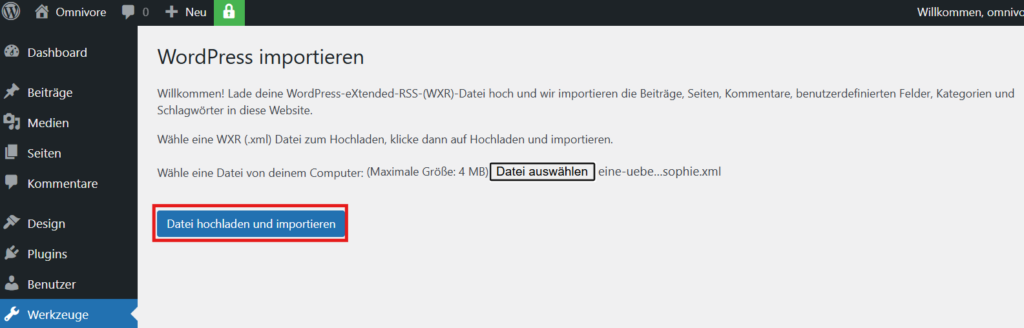
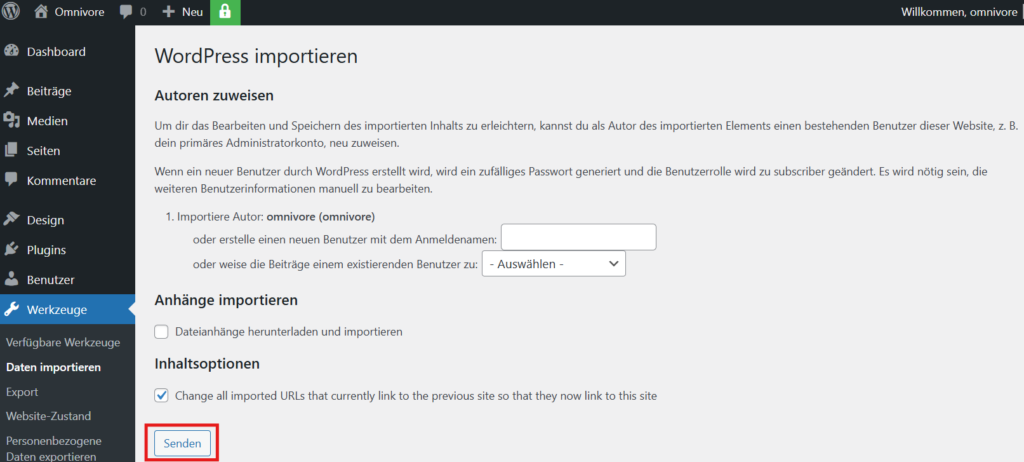
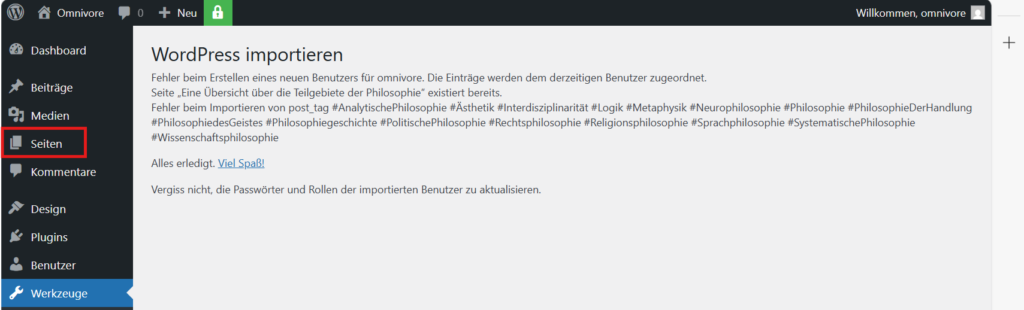
Die Zugriff auf die Seite erfolgt dann über die Liste „Seiten“. Dazu wird die Liste nach Datum absteigend sortiert, so dass die importierte Seite als erste erscheint.
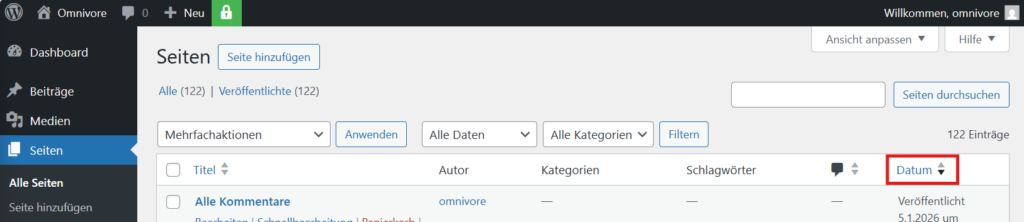
Nach einer zufriedenstellenden Sichtprüfung der Seite kann sie dann in die Seitenstruktur durch Angabe einer eingebunden „Übergeordnet“en Seite eingebunden werden. Der Parameter „menu_order“ bei Seitenerstellung bestimmt dann die Stelle, an der die Seite in die Liste ihrer Geschwisterseiten eingefügt wird.
Inhaltliche Tags
#Prozessautomatisierung #WordPressWorkflow #ChatGPT #PythonSkripte #Quellenmanagement #Texterstellung #PromptEngineering #DigitalePublikation
Ergänzen um Ermittlung und Erklärung relevanter Begriffe für flyouts:
create-prompts.py –exportFile(Seite) -> directory_(Seite).json
insert_flyouts.py –exportFile(Seite) –directoryDir -> exportFile(Seite)_ergänzt
ggf. Löschen von Seite
Reimport von exportFile(Seite)
Ermittlung und Erklärung für LaTex-Formeln entwickeln.
– Latex-Formeln extrahieren
– Beschreibung für Latex-Formeln erzeugen
– flyouts für LaTex-Formeln einfügen
Optimierung des Prompts für die Begriffserklärungen: „Dieser Begriff beschreibt diesen Begriff“ ist als erster Erklärungssatz tautologisch.
Der flyout-content fehlt auf dieser Seite!